Classification Workflow
Tutorial: Classification Tutorial
This topic describes the Classification Workflow in ENVI. This workflow uses unsupervised or supervised methods to categorize pixels in an image into different classes. You can perform an unsupervised classification without providing training data, or you can perform a supervised classification where you provide training data and specify a classification method of maximum likelihood, minimum distance, Mahalanobis distance, or Spectral Angle Mapper (SAM).
You can also write a script to perform classification using the following tasks: ISODATAClassification, MahalanobisDistanceClassification, MaximumLikelihoodClassification, MinimumDistanceClassification, SpectralAngleMapper
See the following for help on a particular step of the workflow:
- Select Input Files for Classification
- Select a Classification Method (unsupervised or supervised)
- Unsupervised Classification Settings
- Supervised Classification Settings
- Clean Up Classification Results
- Export Classification Results
Select Input Files for Classification
- From the Toolbox, select Classification > Classification Workflow. The File Selection panel appears.
- Click Browse and select a panchromatic or multispectral image, using the Data Selection dialog. The Classification workflow accepts any image format listed in Supported Data Types.
- To apply a mask, select the Input Mask tab in the File Selection panel. Masked pixels constitute a separate class in classification output.
- Click Next. The Classification Type panel appears and the file opens in a new workflow view. If the selected file is displayed in an active view before you start the workflow, the display bands and image location are retained, as well as any brightness, contrast, stretch, and sharpen settings. The image location is not retained for pixel-based images or those with pseudo or arbitrary projections.
Select a Classification Method
In the Classification Type panel, select the type of workflow you want to follow, then click Next.
- No Training Data: Opens the Unsupervised Classification panel to begin the unsupervised classification workflow. The unsupervised method does not rely on training data to perform classification.
- Use Training Data: Opens the Supervised Classification panel to begin the supervised classification workflow. The supervised method trains the algorithm by using data from existing ROI files that include representative pixels of the desired classes, or from regions you interactively create on the image.
Unsupervised Classification Settings
Unsupervised classification clusters pixels in a dataset based on statistics only, without requiring you to define training classes.
ISODATA unsupervised classification starts by calculating class means evenly distributed in the data space, then iteratively clusters the remaining pixels using minimum distance techniques. Each iteration recalculates means and reclassifies pixels with respect to the new means. This process continues until the percentage of pixels that change classes during an iteration is less than the change threshold or the maximum number of iterations is reached.
Preview is not available for unsupervised classification, as ENVI would need to process the entire image in order to provide a preview image.
In the Unsupervised Classification panel, set the values to use for classification.
- Enter the Requested Number of Classes to define. The default is 5.
- Click the Advanced tab for additional options.
- Enter the Maximum Iterations to perform. If the Change Threshold % is not met before the maximum number of iterations is reached, the classification process ends. The default is 10.
- Enter the Change Threshold % to specify when to end the classification process. When the percentage of pixels that change classes during an iteration is less than the threshold value, the classification process ends. The default is 2.
- Click Next. The classification process begins, and the status displays on the Unsupervised Classification panel. When the classification process is complete, the Cleanup panel appears.
Supervised Classification Settings
Supervised classification clusters pixels in a dataset into classes based on user-defined training data. The training data can come from an imported ROI file, or from regions you create on the image. The training data must be defined before you can continue in the supervised classification workflow (see Work with Training Data). Once defined, select the classes that you want mapped in the output.
Supervised classification methods include Maximum likelihood, Minimum distance, Mahalanobis distance, and Spectral Angle Mapper (SAM). If you used single-band input data, only Maximum likelihood and Minimum distance are available.
In the Supervised Classification panel, select the Algorithm tab.
- Select the supervised classification method to use from the drop-down list. To optionally adjust parameter settings for the algorithms, see Set Advanced Options:
- Maximum Likelihood: Assumes that the statistics for each class in each band are normally distributed and calculates the probability that a given pixel belongs to a specific class. Each pixel is assigned to the class that has the highest probability (that is, the maximum likelihood). This is the default.
- Minimum Distance: Uses the mean ROIs for each class and calculates the Euclidean distance from each unknown pixel to the mean ROI for each class. The pixels are classified to the nearest class.
- Mahalanobis Distance: A direction-sensitive distance classifier that uses statistics for each class. It is similar to maximum likelihood classification, but it assumes all class covariances are equal, and therefore is a faster method. All pixels are classified to the closest training data.
- Spectral Angle Mapper: (SAM) is a physically-based spectral classification that uses an n-D angle to match pixels to training data. This method determines the spectral similarity between two spectra by calculating the angle between the spectra and treating them as ROIs in a space with dimensionality equal to the number of bands. This technique, when used on calibrated reflectance data, is relatively insensitive to illumination and albedo effects. SAM compares the angle between the training mean ROI and each pixel ROI in n-D space. Smaller angles represent closer matches to the reference spectrum. The pixels are classified to the class with the smallest angle.
-
Define the training data to use for classification. You must define a minimum of two classes, with at least one training sample per class.
You can write a script to calculate training data statistics using the ROIStatistics task or TrainingClassificationStatistics task.
- Enable the Preview check box to preview the settings before processing the data. The preview is calculated only on the area in the view and uses the resolution level at which you are viewing the image. To preview a different area in your image, pan and zoom to the area of interest and re-enable the Preview option. Depending on the algorithm being used by the tool, the preview result might be different from the final result of processing on the full extent, full resolution of the input image in the following scenarios: 1) If you zoomed out of the input raster in the view by 50%, or a percentage less than 50%, ENVI uses a downsampled image at the closest resolution level to calculate the preview, or 2) If the entire image is not visible in the view, ENVI uses the subset in the viewable area of the input image to calculate the preview.
- Click Next. The classification process begins, and the status displays on the Supervised Classification panel. When the classification process is complete, the Cleanup panel appears.
Set Advanced Options
In the Algorithm tab, you can apply no thresholding, one thresholding value for all classes, or different thresholding values for each class. Specifying a different threshold value for each class includes more or fewer pixels in a class. Enabling the Preview check box helps you to preview the adjusted the values. To specify multiple values, select the class in the Training Data tree and enter the value. Press the Enter key to accept the value.
Maximum Likelihood
Set the Probability Threshold to one of the following:
- None: No thresholding.
- Single Value or Multiple Values: Enter a value between 0 and 1 in the Probability Threshold field for all classes (Single Value) or specify a different threshold for each class (Multiple Values). ENVI does not classify pixels with a value lower than this value. The threshold is a probability minimum for inclusion in a class. For example, a value of .9 will include fewer pixels in a class than a setting of .5, because a 90% probability requirement is more strict than allowing a pixel in a class based on a chance of 50%.
Minimum Distance
Set thresholding options for Set Standard Deviations from Mean:
- None: No thresholding.
- Single Value or Multiple Values: Specify the number of standard deviations to use around the mean for all classes (Single Value) or specify a different threshold for each class (Multiple Values). Enter a pixel value between 0 and 107 in the Standard Deviations from Mean field. ENVI does not classify pixels outside this range. The lower the value, the more pixels that are unclassified.
Set thresholding options for Maximum Distance Error:
- None: No thresholding.
-
Single Value or Multiple Values: Enter a pixel value between 0 and 107 in the Distance Error field for all classes (Single Value) or specify a different threshold for each class (Multiple Values). ENVI does not classify pixels outside this range. The smaller the distance threshold, the more pixels that are unclassified.
The pixel of interest must be within both the threshold for distance to mean and the threshold for the standard deviation for a class. The condition for Minimum Distance reduces to the lesser of the two thresholds. A higher value set for each parameter is more inclusive in that more pixels are included in a class for a higher threshold.
If you select None for both parameters, then ENVI classifies all pixels.
Mahalanobis Distance
Set the Maximum Distance Error to one of the following:
- None: No thresholding.
- Single Value or Multiple Values: Enter a pixel value between 0 and 107 in the Distance Error field for all classes (Single Value) or specify a different threshold for each class (Multiple Values). ENVI does not classify pixels outside this range. Mahalanobis Distance accounts for possible non-spherical probability distributions. The distance threshold is the distance within which a class must fall from the center or mean of the distribution for a class. The smaller the distance threshold, the more pixels that are unclassified.
Spectral Angle Mapper
Set the Maximum Spectral Angle to one of he following:
- None: No thresholding.
- Single Value or Multiple Values: Enter a value in radians between 0 and 1.5708 (PI/2) in the Spectral Angle field for all classes (Single Value) or specify a different threshold for each class (Multiple Values). ENVI does not classify pixels with an angle larger than this value. The threshold angle is the angle in radians within which the pixel of interest must lie to be considered part of a class.The lower the value, the more pixels that are unclassified.
Enable the Compute Rule Images check box to export rule images to a file at the end of the workflow and use them to perform additional analysis outside of the Classification workflow, such as apply different stretches or thresholding. Or, in the Rule Classifier to create a new classification image without having to recalculate the entire classification. To compute rule images for the selected classification algorithm, enable the Compute Rule Images check box. The output is a single file containing one rule image per class, with measurements for each pixel related to each class. The measures for the rule images differ based on the classification algorithm you choose. In contrast, the final classification image is a single-band image that contains the final class assignments; pixels are either classified or unclassified.
The pixel values in the rule images are calculated as follows:
Maximum Likelihood classification calculates the following discriminant functions for each pixel in the image:
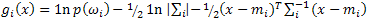
where:
i = the ith class
x = n-dimensional data (where n is the number of bands)
p(ωi) = probability that a class occurs in the image and is assumed the same for all classes
|Σi| = determinant of the covariance matrix of the data in a class
Σi-1 = the inverse of the covariance matrix of a class
mi = mean ROI of a class
Minimum Distance classification calculates the Euclidean distance for each pixel in the image to each class:
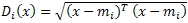
where:
D = Euclidean distance
i = the ith class
x = n-dimensional data (where n is the number of bands)
mi = mean ROI of a class
Mahalanobis Distance classification calculates the Mahalanobis distance for each pixel in the image to each class:
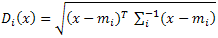
where:
D =Mahalanobis distance
i = the ith class
x = n-dimensional data (where n is the number of bands)
Σi-1 = the inverse of the covariance matrix of a class
mi = mean ROI of a class
Spectral Angle Mapper classification calculates the spectral angle in radians for each pixel in the image to the mean spectral value for each class:
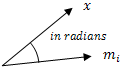
where:
x = n-dimensional data (where n is the number of bands)
mi = mean ROI of a class
Define Training Data
You can load previously-created ROIs from a file, or you can create ROIs interactively on the input image. To provide adequate training data, create a minimum of two classes, with at least one region per class. If you applied a mask to the input data, create training samples within the masked area only.
To load previously defined training data, click the Load Training Data Set button  and select a file that contains training data. Examples include ROIs (
and select a file that contains training data. Examples include ROIs (.roi or .xml) and shapefiles. When you load training data that uses a different projection as the input image, ENVI reprojects it. If the training data uses different extents, the overlapping area is used for training. When you load a training data set from a file, it will replace any ROIs that you drew on the screen previously.
Tip: If you click the Delete Class or Delete All Classes button to remove ROIs, they will no longer be available to re-open through the Data Manager or Layer Manager. If you change your mind and want to re-open one or more ROI classes, click the Reopen ROIs button  and select the ROIs that you need.
and select the ROIs that you need.
You can interactively add additional ROIs to an existing ROI layer that you imported, and you can create new ROI layers.
- To add an ROI to an existing training data class, select the class from the Training Data tree, and use the cursor to draw on the desired area of the input image.
- To add a new ROI class, click the Add Class button
 . Use the cursor to draw the polygon on the desired area of the input image.
. Use the cursor to draw the polygon on the desired area of the input image. - To delete a class, select the class and click the Delete Class button
 .
. - To save the training data, click the Save Training Data Set button
 .
.
You can change the following properties in the Properties tab of the Supervised Classification panel:
- Class Name: The name of the class that will be output in the results. Enter a new name in the Class Name field to replace the default.
- Class Color: The color that will display for that class in the results. Click on the Class Color drop-down list to select a new color.
Clean Up Classification Results
The optional Cleanup step refines the classification result. You can preview the refinement before you apply the settings.
Tip: Cleanup is recommended if you plan to save the classification vectors to a file in the final step of the workflow. Performing cleanup significantly reduces the time needed to export classification vectors. To write a script that performs cleanup, use the ClassificationAggregation and ClassificationSmoothing tasks.
- Enable the check boxes for the cleanup methods you want to use. The following are available:
- Enable Smoothing: removes speckling noise during cleanup.
- Enable Aggregation: removes small regions.
- Enter values for the cleanup methods you enabled:
- Specify the Smooth Kernel Size using an odd number (e.g., 3 = 3x3 pixels). The square kernel's center pixel will be replaced with the majority class value of the kernel. The default is 3.
- Specify the Aggregate Minimum Size in pixels. Regions with a size of this value or smaller are aggregated to an adjacent, larger region. The default is 9.
- Enable the Preview option to see the cleanup results in a Preview Window before processing the entire image. You can change the cleanup settings and preview the results again, as needed.
- Click Next. The Export panel appears.
Export Classification Results
You can write a script to export classification results to a vector using the ClassificationToShapefile task. Or, export classification results to ROIs using the ClassificationToPixelROI task and ClassificationToPolygonROI task.
- In the Export Files tab in the Export panel, enable the output options you want. The following are available:
- Export Classification Image saves the classification result to an ENVI classification file.
-
Export Classification Vectors saves the vectors created during classification to a shapefile. The output area units are in square meters.
Note: Depending on the image size, exporting to vectors may be time-consuming. Performing the Cleanup step is recommended before exporting to vectors.
- In the Additional Export tab, enable any other output options you want. The following are available:
- Export Classification Statistics saves the classification statistics to a text file. The output area units are in square meters.
- Export Rule Images saves the rule images to ENVI raster format. This option is available if you performed supervised classification and you enabled the Compute Rule Images option in the Algorithm tab of the Supervised Classification panel.
- Click Finish to create the output, add the new layers to the Layer Manager, and save the files to the directories you specified. When the export is complete, the workflow view closes. The original data and the export data display in the Image window view. The classes display in the Layer Manager as children of the raster.
- You can convert the exported vectors to ROIs, which is described in Region of Interest (ROI) Tool.
See Also
ENVI Classification Files, Class Layers, Classification Tools, Classification Tutorial, Thematic Change Detection